1. 简介
Antlr (ANother Tool for Language Recognition) 是一个强大的跨语言语法解析器,可以用来读取、处理、执行或翻译结构化文本或二进制文件。它被广泛用来构建语言,工具和框架。Antlr可以从语法上来生成一个可以构建和遍历解析树的解析器。2. 谁在使用
- Hive
- Spark
- Oracle
- Presto
- Elasticsearch
3. 常见的语法分析器
- Antlr
- Javacc
- SqlParser (位于
Alibaba的Druid库中)
其中Antlr和Javacc都是现代的语法解析器,两者都很优秀,其中Antlr要更胜一筹。而SqlParser只能解析sql语句,功能比较单一。
:本人基于Antlr和SqlParser分别写了一套elasticsearch-sql组件,有需要的人可以看看源码。
4. 基本概念
- 抽象语法树 (Abstract Syntax Tree,AST) 抽象语法树是源代码结构的一种抽象表示,它以树的形状表示语言的语法结构。抽象语法树一般可以用来进行
代码语法的检查,代码风格的检查,代码的格式化,代码的高亮,代码的错误提示以及代码的自动补全等等。 - 语法解析器 (Parser) 语法解析器通常作为
编译器或解释器出现。它的作用是进行语法检查,并构建由输入单词(Token)组成的数据结构(即抽象语法树)。语法解析器通常使用词法分析器(Lexer)从输入字符流中分离出一个个的单词(Token),并将单词(Token)流作为其输入。实际开发中,语法解析器可以手工编写,也可以使用工具自动生成。 - 词法分析器 (Lexer)
词法分析是指在计算机科学中,将字符序列转换为单词(Token)的过程。执行词法分析的程序便称为词法分析器。词法分析器(Lexer)一般是用来供语法解析器(Parser)调用的。
5. Antlr4使用方法
(1). 安装
cd /usr/local/lib
wget</span> https://www.antlr.org/download/antlr-4.8-complete.jar
export CLASSPATH=".:/usr/local/lib/antlr-4.8-complete.jar:$CLASSPATH"
antlr4='java -jar /usr/local/lib/antlr-4.8-complete.jar'
grun='java org.antlr.v4.gui.TestRig'但是本文并不使用这种方式来使用Antlr4,而是使用插件的方式。
(2). 安装插件
本文使用IDEA作为开发工具,在Preference->Plugins中搜索antlr然后安装即可。
(3). 定义DSL语法
本文将使用Antlr4实现一个简化版的Elasticsearch的查询语法,代替Elasticsearch的dsl。
搜索语法定义如下:
单个查询:field:value,其中冒号:和等于号=表示等于,!=表示不等于
多个查询:field1:value1,field2:value2,使用逗号,或者&&表示且的关系,使用||表示或的关系
括号:可以使用括号()将多个条件扩起来
示例:
country:中国,province:湖南,city:张家界
生成的抽象语法树如下所示:


聚类语法定义如下:
桶聚类(terms):field
去重值计数(cardinality):(field)
桶聚类分页(composite):fieldaftervalue
地理边框聚类(geoBoundingBox):[field]
桶聚类嵌套子聚类(subAgg):field1>field2>field3
多个聚类条件用分号;隔开
示例:
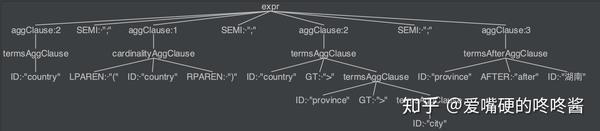
country;(country);country>province>city;province after 湖南
生成的抽象语法树如下所示:
(4). 编写Antlr4语法文件
创建SearchLexer.g4文件,定义词法分析器的Token
// 表明SearchLexer.g4文件是词法分析器(lexer)定义文件
// 词法分析器的名称一定要和文件名保持一致
lexer grammar SearchLexer;
channels {
ESQLCOMMENT,
ERRORCHANNEL
}
//SKIP 当Antlr解析到下面的代码时,会选择跳过
// 遇到 \t\r\n 会忽略
SPACE: [ \t\r\n]+ -> channel(HIDDEN);
// 遇到 /*! */ 会当作注释跳过
SPEC_ESSQL_COMMENT: '/*!' .+? '*/' -> channel(ESQLCOMMENT);
// 遇到 /* */ 会当作注释跳过
COMMENT_INPUT: '/*' .*? '*/' -> channel(HIDDEN);
// 遇到 -- 会当作注释跳过
// 遇到 # 会当作注释跳过
LINE_COMMENT: (
('-- ' | '#') ~[\r\n]* ('\r'? '\n' | EOF)
| '--' ('\r'? '\n' | EOF)
) -> channel(HIDDEN);
// 定义Token,模式为 {field}:{value}
MINUS: '-'; //使MINUS和-等价,以下同理
STAR: '*';
COLON: ':'|'\uFF1A';
EQ: '=';
NE: '!=';
BOOLOR: '||'|'|'; // 使BOOLOR与||或者|等价
BOOLAND: '&&'|COMMA|'&';
//CONSTRUCTORS
DOT: '.' -> mode(AFTER_DOT);
LBRACKET: '[';
RBRACKET: ']';
LPAREN: '(';
RPAREN: ')';
COMMA: ','|'\uFF0C'; // 使COMMA与,或,等价(\uFF0C表示,的unicode编码)
SEMI: ';';
GT: '>';
// 这里和以下代码等价
// AFTER: 'after' 但是这种代码只能表示小写的after,是大小写区分的,这样不好
// 通过下面定义的fragment,将AFTER用A F T E R表示,一定要每个字母空一格,就可以不区分大小写了
// 所有语法的关键字都建议使用这种方式声明
AFTER: A F T E R;
SINGLE_QUOTE: '\'';
DOUBLE_QUOTE: '"';
REVERSE_QUOTE: '`';
UNDERLINE: '_';
CHINESE: '\u4E00'..'\u9FA5'; //表示所有中文的unicode编码,以支持中文
ID: (CHINESE|ID_LETTER|DOT|MINUS|UNDERLINE|INT|FLOAT|REVERSE_QUOTE|DOUBLE_QUOTE|SINGLE_QUOTE)+;
// ? 表示可有可无
// + 表示至少有一个
// | 表示或的关系
// * 表示有0或者多个
INT: MINUS? DEC_DIGIT+;
FLOAT: (MINUS? DEC_DIGIT+ DOT DEC_DIGIT+)| (MINUS? DOT DEC_DIGIT+);
// 使用DEC_DIGIT代表0到9之间的数字
fragment DEC_DIGIT: [0-9];
// 使用ID_LETTER代表a-z的大写小写字母和_
fragment ID_LETTER: [a-zA-Z]| UNDERLINE;
// 表示用A代表a和A,这样就可以不区分大小写了,以下同理
fragment A: [aA];
fragment B: [bB];
fragment C: [cC];
fragment D: [dD];
fragment E: [eE];
fragment F: [fF];
fragment G: [gG];
fragment H: [hH];
fragment I: [iI];
fragment J: [jJ];
fragment K: [kK];
fragment L: [lL];
fragment M: [mM];
fragment N: [nN];
fragment O: [oO];
fragment P: [pP];
fragment Q: [qQ];
fragment R: [rR];
fragment S: [sS];
fragment T: [tT];
fragment U: [uU];
fragment V: [vV];
fragment W: [wW];
fragment X: [xX];
fragment Y: [yY];
fragment Z: [zZ];
mode AFTER_DOT;
//DEFAULT_MODE是Antlr中默认定义好的mode
DOTINTEGER: ( '0' | [1-9] [0-9]*) -> mode(DEFAULT_MODE);
DOTID: [_a-zA-Z] [_a-zA-Z0-9]* -> mode(DEFAULT_MODE);
创建SearchParser.g4文件,定义语法解析器的搜索语法
// 表明SearchParser.g4文件是语法解析器(parser)定义文件
// 同理,语法分析器的名称一定要和文件名保持一致
parser grammar SearchParser;
options {
// 表示解析token的词法解析器使用SearchLexer
tokenVocab = SearchLexer;
}
// EOF(end of file)表示文件结束符,这个是Antlr中已经定义好的
prog: expression | STAR EOF;
expression:
// 表示表达式可以被括号括起来
// 如果语法后面加上了#{name},相当于将这个name作为这个语法块的名字,这个#{name}要加都得加上,要不加都不加
// (country:中国)
LPAREN expression RPAREN #lrExpr
// leftExpr是给定义的语法起的别名(alias),可有可无,但是有会更好点
// 因为antlr解析同一语法块的同一类token时,会将他们放在一个list里面
// 比如下面的语法块,有两个expression,antlr会将他们放在一个列表expressions里
// 获取第一个expression时需要expressions.get(0),获取第二个expression时需要expressions.get(1)
// 如果给第一个expression起了个别名叫leftExpr,给第二个expression起了个别名叫rightExpr
// 那样在java里面调用时就可以直接调用leftExpr和rightExpr,而不需要指定expressions中的索引(0或1)
// 这样做的好处是:如果之后添加了新的token,比如在下面语法中间添加一个expression的token
// 这时如果不使用别名leftExpr,rightExpr就可能需要修改java代码,因为原来rightExpr对应的expression在expressions中索引变为2了
// 使用别名leftExpr,rightExpr(当然还可以取别的名字)就没有这个问题,使语法文件和生成的java代码更便于维护
// country:中国
| leftExpr = expression operator = (EQ |COLON| NE ) rightExpr = expression #eqExpr
// (country:中国||country:美国)&&city:北京
| leftExpr = expression operator = (BOOLAND|BOOLOR) rightExpr = expression #boolExpr
// country等字面量
| ID #identityExpr
;
创建AggregateParser.g4文件,定义语法解析器的聚类语法
parser grammar AggregateParser;
options {
// 聚类的语法分析器也可以使用SearchLexer
tokenVocab = SearchLexer;
}
expr:
// 多个聚类条件用分号隔开
aggClause (SEMI aggClause)*
;
// aggClause表示代表以下聚类的任意一种
aggClause:
cardinalityAggClause|termsAggClause|termsAfterAggClause|geoBoundingBoxAggClause
;
// 去重值计数 -> (country)
cardinalityAggClause:
LPAREN ID RPAREN
;
// 桶聚类分页 -> province after 湖南
termsAfterAggClause:
field = ID AFTER after=ID
;
// 桶聚类嵌套子聚类 -> country>province>city
termsAggClause:
field = ID (GT termsAggClause)?
;
// 地理边框聚类 -> [coordinate]
geoBoundingBoxAggClause:
LBRACKET ID RBRACKET
;
(5). 使用Antlr4自动生成代码文件
在IDEA中,在SearchParser.g4,AggregateParser.g4文件右键选择Configure ANTLR...,配置每个文件生成代码的配置和输出目录
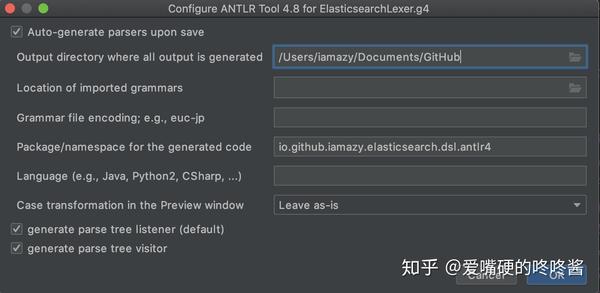
然后在SearchParser.g4,AggregateParser.g4文件右键选择Generate ANTLR Recognizer生成代码文件。生成的代码结构如下所示:
|-- io
|-- github
|-- iamazy
|-- elasticsearch
|-- dsl
|-- antlr4
|-- AggregateParser.interp
|-- AggregateParser.java
|-- AggregateParser.tokens
|-- AggregateParserBaseListener.java
|-- AggregateParserBaseVisitor.java
|-- AggregateParserListener.java
|-- AggregateParserVisitor.java
|-- AggregateWalker.java //这是自己创建的文件,不是antlr自动生成的
|-- QueryParser.java //这是自己创建的文件,不是antlr自动生成的
|-- SearchLexer.interp
|-- SearchLexer.java
|-- SearchLexer.tokens
|-- SearchParser.interp
|-- SearchParser.java
|-- SearchParser.tokens
|-- SearchParserBaseListener.java
|-- SearchParserBaseVisitor.java
|-- SearchParserListener.java
|-- SearchParserVisitor.java
|-- SearchWalker.java //这是自己创建的文件,不是antlr自动生成的
(6). 遍历抽象语法树
这里我们不实现Antlr生成好的Listener或Visitor遍历抽象语法树的接口,而是自己写代码遍历抽象语法树
在io.github.iamazy.elasticsearch.dsl.antlr4包下创建Java类SearchWalker,AggregateWalker,QueryParser。
SearchWalker类文件内容如下:package io.github.iamazy.elasticsearch.antlr4;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.apache.commons.lang3.StringUtils;
/**
* @descrition 生成遍历搜索条件的抽象语法树的遍历器
**/
class SearchWalker{
private String expression;
SearchWalker(String expression){
this.expression=expression;
}
SearchParser buildAntlrTree(){
if(StringUtils.isBlank(this.expression)){
throw new RuntimeException("搜索表达式不能为空!!!");
}
CharStream stream= CharStreams.fromString(this.expression);
SearchLexer lexer=new SearchLexer(stream);
return new SearchParser(new CommonTokenStream(lexer));
}
}AggregateWalker类文件内容如下:package io.github.iamazy.elasticsearch.antlr4;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.apache.commons.lang3.StringUtils;
/**
* @descrition 生成遍历聚类条件的抽象语法树的遍历器
**/
class AggregateWalker {
private String expression;
AggregateWalker(String expression){
this.expression=expression;
}
AggregateParser buildAntlrTree(){
if(StringUtils.isBlank(this.expression)){
throw new RuntimeException("搜索表达式不能为空!!!");
}
CharStream stream= CharStreams.fromString(this.expression);
SearchLexer lexer=new SearchLexer(stream);
return new AggregateParser(new CommonTokenStream(lexer));
}
}QueryParser类文件内容如下:package io.github.iamazy.elasticsearch.antlr4;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.composite.CompositeAggregationBuilder;
import org.elasticsearch.search.aggregations.bucket.composite.CompositeValuesSourceBuilder;
import org.elasticsearch.search.aggregations.bucket.composite.TermsValuesSourceBuilder;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @descrition 遍历搜索条件和聚类条件的抽象语法树
**/
public class QueryParser {
public QueryBuilder parse(String expr) {
//如果表达式为*,则返回全部数据
if ("*".equals(expr.trim())) {
return QueryBuilders.matchAllQuery();
}
//生成遍历树的实例
SearchWalker walker = new SearchWalker(expr);
//调用方法,遍历表达式
SearchParser searchParser = walker.buildAntlrTree();
//将搜索表达式转换为查询elasticsearch的querybuilder
return parseExpressionContext(searchParser.prog().expression());
}
private QueryBuilder parseExpressionContext(SearchParser.ExpressionContext expressionContext) {
//如果表达式是被括号包含的话,调用parseLrExprContext
if (expressionContext instanceof SearchParser.LrExprContext) {
return parseLrExprContext((SearchParser.LrExprContext) expressionContext);
}
//如果表达式是条件表达式包含与或非的话,调用parseBoolExprContext
else if (expressionContext instanceof SearchParser.BoolExprContext) {
return parseBoolExprContext((SearchParser.BoolExprContext) expressionContext);
}
//如果表达式是等式的话,调用parseEqExprContext
else if (expressionContext instanceof SearchParser.EqExprContext) {
return parseEqExprContext((SearchParser.EqExprContext) expressionContext);
}
else {
//不满足上述条件,则抛出异常
throw new RuntimeException("不支持该查询语法!!!");
}
}
//解析括号中的表达式
private QueryBuilder parseLrExprContext(SearchParser.LrExprContext lrExprContext) {
SearchParser.ExpressionContext expression = lrExprContext.expression();
return parseExpressionContext(expression);
}
private BoolQueryBuilder parseBoolExprContext(SearchParser.BoolExprContext boolExprContext) {
//解析条件表达式的左半边表达式
SearchParser.ExpressionContext leftExpr = boolExprContext.expression(0);
//解析条件表达式的右半边表达式
SearchParser.ExpressionContext rightExpr = boolExprContext.expression(1);
//将左半边表达式转换成querybuilder
QueryBuilder leftQuery = parseExpressionContext(leftExpr);
//将右半边表达式转换为querybuilder
QueryBuilder rightQuery = parseExpressionContext(rightExpr);
//如果表达式表示的是且的关系
if (boolExprContext.BOOLAND() != null) {
return QueryBuilders.boolQuery().must(leftQuery).must(rightQuery);
} else {
//如果表达式表示的是或的关系
return QueryBuilders.boolQuery().should(leftQuery).should(rightQuery);
}
}
private QueryBuilder parseEqExprContext(SearchParser.EqExprContext eqExprContext) {
String field, value;
//如果左半边的字段值
if (eqExprContext.leftExpr instanceof SearchParser.IdentityExprContext) {
//获取该字段实际的映射字段
field = parseIdentityContext((SearchParser.IdentityExprContext) eqExprContext.leftExpr);
} else {
//否则抛出异常
throw new RuntimeException("不支持该查询语法!!!");
}
//如果右半边是个值
if (eqExprContext.rightExpr instanceof SearchParser.IdentityExprContext) {
//则不动
value = parseIdentityContext((SearchParser.IdentityExprContext) eqExprContext.rightExpr);
} else {
//否则抛出异常
throw new RuntimeException("不支持该查询语法!!!");
}
//如果条件表达式的关联条件是不等于
if (eqExprContext.NE() != null) {
//则调用must_not
return QueryBuilders.boolQuery().mustNot(QueryBuilders.termQuery(field, value));
}
//如果条件表达式的关联条件是冒号或者等于号
return QueryBuilders.termQuery(field, value);
}
//解析字段名和字段值
private String parseIdentityContext(SearchParser.IdentityExprContext identityExprContext) {
return identityExprContext.getText();
}
//解析聚类表达式
public List<AggregationBuilder> parseAggregationExpr(String expr) {
//生成聚类遍历树实例
AggregateWalker walker = new AggregateWalker(expr);
//遍历聚类表达式
AggregateParser aggregateParser = walker.buildAntlrTree();
//将聚类表达式转换成elasticsearch的aggregationbuilder的列表
return parseAggregationContext(aggregateParser.expr().aggClause());
}
private List<AggregationBuilder> parseAggregationContext(List<AggregateParser.AggClauseContext> aggClauseContexts) {
//创建aggregationbuilder空列表
List<AggregationBuilder> aggregationBuilders = new ArrayList<>(0);
//是否支持聚类分页,默认值为false
boolean hasCompositeAggregation = false;
//创建CompositeValuesSourceBuilder的列表
List<CompositeValuesSourceBuilder<?>> compositeValuesSourceBuilders = new ArrayList<>(0);
//创建afterkey的map
Map<String, Object> afterKeys = new HashMap<>(0);
//对聚类表达式进行遍历
for (AggregateParser.AggClauseContext aggClauseContext : aggClauseContexts) {
//如果聚类表达式形如(ip),则调用AggregationBuilders.cardinality方法,并添加到聚类列表中
if (aggClauseContext.cardinalityAggClause() != null) {
//获取聚类字段名
String field = aggClauseContext.cardinalityAggClause().ID().getText();
//将转换后的字段掺入AggregationBuilders.cardinality方法中
aggregationBuilders.add(AggregationBuilders.cardinality(field + "_cardinality").field(field));
}
//如果聚类表达式形如country after 湖南,则调用CompositeValuesSourceBuilder进行聚类分页
else if (aggClauseContext.termsAfterAggClause() != null) {
//获取字段值
String field = aggClauseContext.termsAfterAggClause().field.getText();
//将是否聚类分页字段设置为true
hasCompositeAggregation = true;
//获取after的值
String after = aggClauseContext.termsAfterAggClause().after.getText();
//设置查询的名称
String compositeField = aggClauseContext.termsAfterAggClause().field.getText() + "_composite";
//生成聚类分页的实例
CompositeValuesSourceBuilder sourceBuilder = new TermsValuesSourceBuilder(compositeField).field(field);
//添加到聚类分页的列表中
compositeValuesSourceBuilders.add(sourceBuilder);
afterKeys.put(compositeField, after);
}
//如果聚类表达式形如[coordinate],则进行地理边框聚类
else if (aggClauseContext.geoBoundingBoxAggClause() != null) {
//获取地理字段的值
String field = aggClauseContext.geoBoundingBoxAggClause().ID().getText();
//添加到聚类列表中
aggregationBuilders.add(AggregationBuilders.geoBounds(field + "_geoBound").field(field));
}
//如果聚类表达式形如ip,则对其进行桶聚类
else if (aggClauseContext.termsAggClause() != null) {
//将转换后的桶聚类实例添加到聚类列表中
aggregationBuilders.add(parseTermsAggregationContext(aggClauseContext.termsAggClause()));
}
}
//如果请求中存在聚类分页
if (hasCompositeAggregation) {
CompositeAggregationBuilder composite = AggregationBuilders.composite("composites", compositeValuesSourceBuilders).size(15);
//则设置聚类分页的值,但每次请求只支持一个字段进行分页
composite.aggregateAfter(afterKeys);
aggregationBuilders.add(composite);
if (compositeValuesSourceBuilders.size() > 1) {
throw new RuntimeException("暂不支持多字段分页功能");
}
}
return aggregationBuilders;
}
//解析桶聚类表达式,形如ip
private AggregationBuilder parseTermsAggregationContext(AggregateParser.TermsAggClauseContext termsAggClauseContext) {
//获取字段名
String field = termsAggClauseContext.field.getText();
//生成桶聚类实例
AggregationBuilder aggregationBuilder = AggregationBuilders.terms(field + "_terms").field(field).size(5000);
if (termsAggClauseContext.termsAggClause() != null) {
//如果桶聚类下有子聚类,则添加子聚类
aggregationBuilder.subAggregation(parseTermsAggregationContext(termsAggClauseContext.termsAggClause()));
}
return aggregationBuilder;
}
}(7). 将查询语句转换成Elasticsearch DSL
在main方法(或其他调用解析器的方法)中
public static void main(String[] args) {
QueryParser queryParser=new QueryParser();
//将搜索条件转换成QueryBuilder
QueryBuilder queryBuilder = queryParser.parse("country:中国,province:湖南,city:张家界");
//然后将queryBuilder传给Elasticsearch进行查询
//将聚类条件转换成List<AggregationBuilder>
List<AggregationBuilder> aggregationBuilders = queryParser.parseAggregationExpr("country,(country),country>province>city,province after 湖南");
//然后将aggregationBuilders传给Elasticsearch进行聚类
...
}6. 推荐阅读
Antlr4官方指南
Antlr4官方示例:Grammars-v4

