中国科大 LUG 的 在 LUG HTTP 代理服务器上部署了 Linux 4.9 的 TCP BBR 拥塞控制算法。从科大的移动出口到新加坡 DigitalOcean 的实测下载速度从 647 KB/s 提高到了 22.1 MB/s(截屏如下)。


此次 Google 提交到 Linux 主线并发表在 ACM queue 期刊上的 TCP BBR 拥塞控制算法,继承了 Google “先在生产环境部署,再开源和发论文” 的研究传统。TCP BBR 已经在 Youtube 服务器和 Google 跨数据中心的内部广域网(B4)上部署。
TCP BBR 致力于解决两个问题:- 在有一定丢包率的网络链路上充分利用带宽。
- 降低网络链路上的 buffer 占用率,从而降低延迟。
TCP 拥塞控制的目标是最大化利用网络上瓶颈链路的带宽。一条网络链路就像一条水管,要想用满这条水管,最好的办法就是给这根水管灌满水,也就是:
水管内的水的数量 = 水管的容积 = 水管粗细 × 水管长度
换成网络的名词,也就是:
网络内尚未被确认收到的数据包数量 = 网络链路上能容纳的数据包数量 = 链路带宽 × 往返延迟
TCP 维护一个发送窗口,估计当前网络链路上能容纳的数据包数量,希望在有数据可发的情况下,回来一个确认包就发出一个数据包,总是保持发送窗口那么多个包在网络中流动。
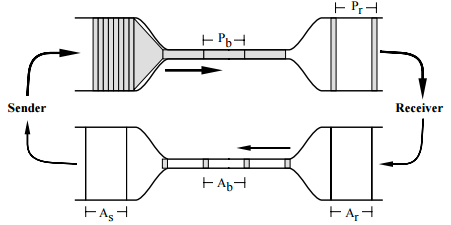
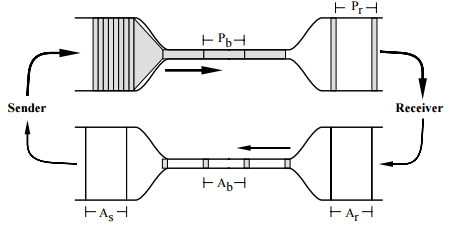
TCP 与水管的类比示意(图片来源:Van Jacobson,Congestion Avoidance and Control,1988)
如何估计水管的容积呢?一种大家都能想到的方法是不断往里灌水,直到溢出来为止。标准 TCP 中的拥塞控制算法也类似:不断增加发送窗口,直到发现开始丢包。这就是所谓的 ”加性增,乘性减”,也就是当收到一个确认消息的时候慢慢增加发送窗口,当确认一个包丢掉的时候较快地减小发送窗口。
标准 TCP 的这种做法有两个问题:
首先,假定网络中的丢包都是由于拥塞导致(网络设备的缓冲区放不下了,只好丢掉一些数据包)。事实上网络中有可能存在传输错误导致的丢包,基于丢包的拥塞控制算法并不能区分拥塞丢包和错误丢包。在数据中心内部,错误丢包率在十万分之一(1e-5)的量级;在广域网上,错误丢包率一般要高得多。
更重要的是,“加性增,乘性减” 的拥塞控制算法要能正常工作,错误丢包率需要与发送窗口的平方成反比。数据中心内的延迟一般是 10-100 微秒,带宽 10-40 Gbps,乘起来得到稳定的发送窗口为 12.5 KB 到 500 KB。而广域网上的带宽可能是 100 Mbps,延迟 100 毫秒,乘起来得到稳定的发送窗口为 10 MB。广域网上的发送窗口比数据中心网络高 1-2 个数量级,错误丢包率就需要低 2-4 个数量级才能正常工作。因此标准 TCP 在有一定错误丢包率的长肥管道(long-fat pipe,即延迟高、带宽大的链路)上只会收敛到一个很小的发送窗口。这就是很多时候客户端和服务器都有很大带宽,运营商核心网络也没占满,但下载速度很慢,甚至下载到一半就没速度了的一个原因。
其次,网络中会有一些 buffer,就像输液管里中间膨大的部分,用于吸收网络中的流量波动。由于标准 TCP 是通过 “灌满水管” 的方式来估算发送窗口的,在连接的开始阶段,buffer 会被倾向于占满。后续 buffer 的占用会逐渐减少,但是并不会完全消失。客户端估计的水管容积(发送窗口大小)总是略大于水管中除去膨大部分的容积。这个问题被称为 bufferbloat(缓冲区膨胀)。
缓冲区膨胀现象图示缓冲区膨胀有两个危害:
- 增加网络延迟。buffer 里面的东西越多,要等的时间就越长嘛。
- 共享网络瓶颈的连接较多时,可能导致缓冲区被填满而丢包。很多人把这种丢包认为是发生了网络拥塞,实则不然。
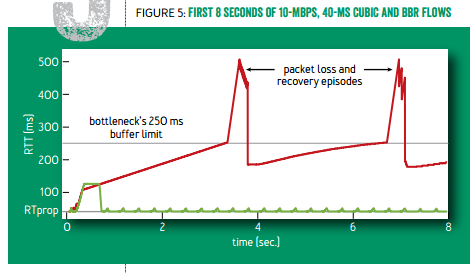
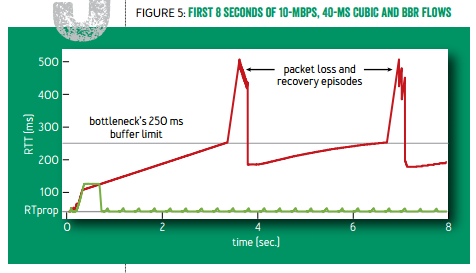
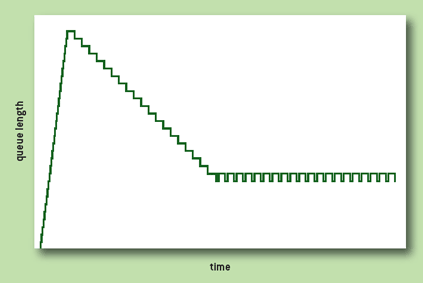
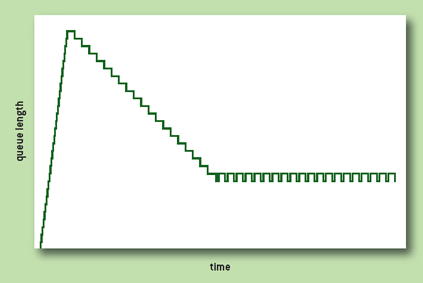
往返延迟随时间的变化。红线:标准 TCP(可见周期性的延迟变化,以及 buffer 几乎总是被填满);绿线:TCP BBR
(图片引自 Google 在 ACM queue 2016 年 9-10 月刊上的论文 [1],下同)
有很多论文提出在网络设备上把当前缓冲区大小的信息反馈给终端,比如在数据中心广泛应用的 ECN(Explicit Congestion Notification)。然而广域网上网络设备众多,更新换代困难,需要网络设备介入的方案很难大范围部署。
TCP BBR 是怎样解决以上两个问题的呢?- 既然不容易区分拥塞丢包和错误丢包,TCP BBR 就干脆不考虑丢包。
- 既然灌满水管的方式容易造成缓冲区膨胀,TCP BBR 就分别估计带宽和延迟,而不是直接估计水管的容积。
带宽和延迟的乘积就是发送窗口应有的大小。发明于 2002 年并已进入 Linux 内核的 TCP Westwood 拥塞控制算法,就是分别估计带宽和延迟,并计算其乘积作为发送窗口。然而带宽和延迟就像粒子的位置和动量,是没办法同时测准的:要测量最大带宽,就要把水管灌满,缓冲区中有一定量的数据包,此时延迟就是较高的;要测量最低延迟,就要保证缓冲区为空,网络里的流量越少越好,但此时带宽就是较低的。
TCP BBR 解决带宽和延迟无法同时测准的方法是:交替测量带宽和延迟;用一段时间内的带宽极大值和延迟极小值作为估计值。
在连接刚建立的时候,TCP BBR 采用类似标准 TCP 的慢启动,指数增长发送速率。然而标准 TCP 遇到任何一个丢包就会立即进入拥塞避免阶段,它的本意是填满水管之后进入拥塞避免,然而(1)如果链路的错误丢包率较高,没等到水管填满就放弃了;(2)如果网络里有 buffer,总要把缓冲区填满了才会放弃。
TCP BBR 则是根据收到的确认包,发现有效带宽不再增长时,就进入拥塞避免阶段。(1)链路的错误丢包率只要不太高,对 BBR 没有影响;(2)当发送速率增长到开始占用 buffer 的时候,有效带宽不再增长,BBR 就及时放弃了(事实上放弃的时候占的是 3 倍带宽 × 延迟,后面会把多出来的 2 倍 buffer 清掉),这样就不会把缓冲区填满。
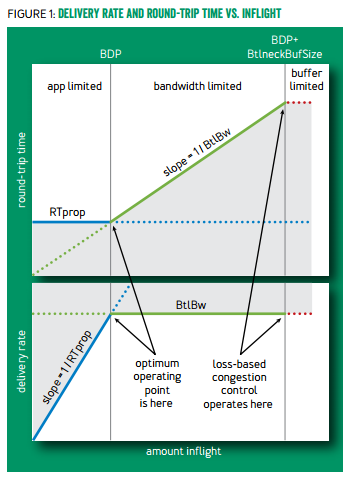
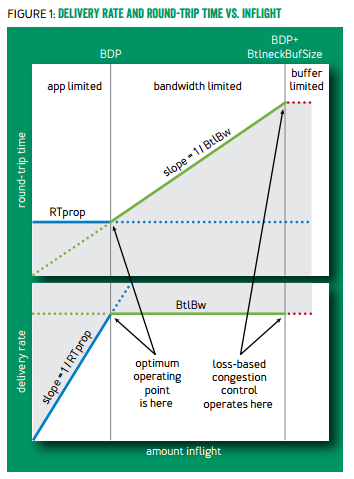
在慢启动过程中,由于 buffer 在前期几乎没被占用,延迟的最小值就是延迟的初始估计;慢启动结束时的最大有效带宽就是带宽的初始估计。
慢启动结束后,为了把多占用的 2 倍带宽 × 延迟消耗掉,BBR 将进入排空(drain)阶段,指数降低发送速率,此时 buffer 里的包就被慢慢排空,直到往返延迟不再降低。如下图绿线所示。
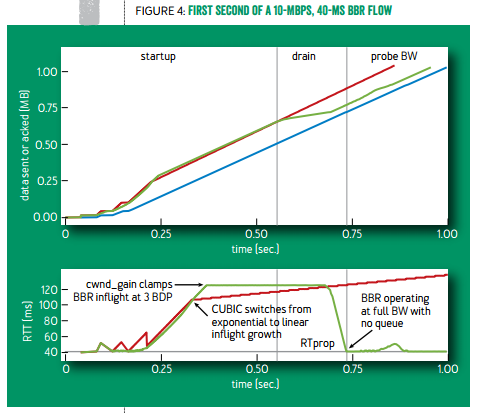
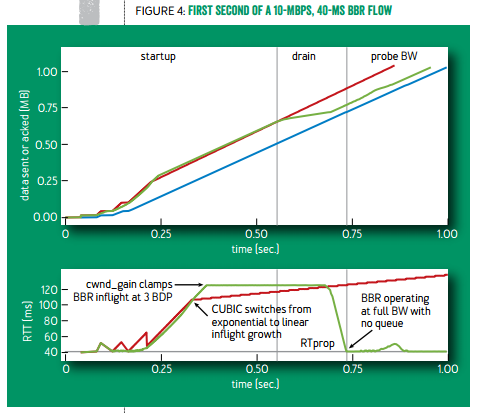
TCP BBR(绿线)与标准 TCP(红线)有效带宽和往返延迟的比较
排空阶段结束后,BBR 进入稳定运行状态,交替探测带宽和延迟。由于网络带宽的变化比延迟的变化更频繁,BBR 稳定状态的绝大多数时间处于带宽探测阶段。带宽探测阶段是一个正反馈系统:定期尝试增加发包速率,如果收到确认的速率也增加了,就进一步增加发包速率。
具体来说,以每 8 个往返延迟为周期,在第一个往返的时间里,BBR 尝试增加发包速率 1/4(即以估计带宽的 5/4 速度发送)。在第二个往返的时间里,为了把前一个往返多发出来的包排空,BBR 在估计带宽的基础上降低 1/4 作为发包速率。剩下 6 个往返的时间里,BBR 使用估计的带宽发包。
当网络带宽增长一倍的时候,每个周期估计带宽会增长 1/4,每个周期为 8 个往返延迟。其中向上的尖峰是尝试增加发包速率 1/4,向下的尖峰是降低发包速率 1/4(排空阶段),后面 6 个往返延迟,使用更新后的估计带宽。3 个周期,即 24 个往返延迟后,估计带宽达到增长后的网络带宽。
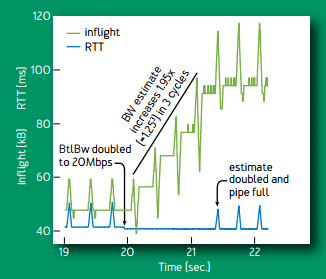
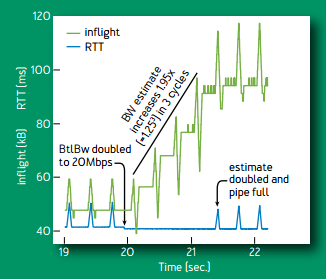
网络带宽增长一倍时的行为。绿线为网络中包的数量,蓝线为延迟
当网络带宽降低一半的时候,多出来的包占用了 buffer,导致网络中包的延迟显著增加(下图蓝线),有效带宽降低一半。延迟是使用极小值作为估计,增加的实际延迟不会反映到估计延迟(除非在延迟探测阶段,下面会讲)。带宽的估计则是使用一段滑动窗口时间内的极大值,当之前的估计值超时(移出滑动窗口)之后,降低一半后的有效带宽就会变成估计带宽。估计带宽减半后,发送窗口减半,发送端没有窗口无法发包,buffer 被逐渐排空。
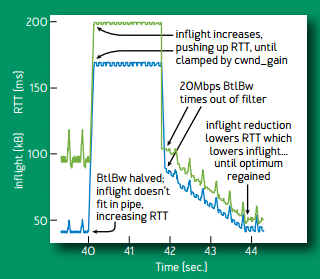
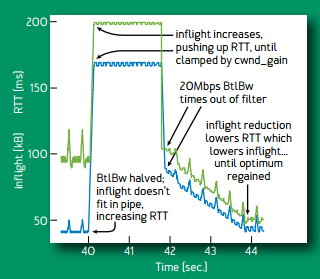
当带宽增加一倍时,BBR 仅用 1.5 秒就收敛了;而当带宽降低一半时,BBR 需要 4 秒才能收敛。前者由于带宽增长是指数级的;后者主要是由于带宽估计采用滑动窗口内的极大值,需要一定时间有效带宽的下降才能反馈到带宽估计中。
当网络带宽保持不变的时候,稳定状态下的 TCP BBR 是下图这样的:(我们前面看到过这张图)可见每 8 个往返延迟为周期的延迟细微变化。

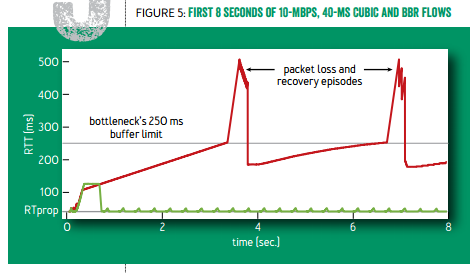
往返延迟随时间的变化。红线:标准 TCP;绿线:TCP BBR
上面介绍了 BBR 稳定状态下的带宽探测阶段,那么什么时候探测延迟呢?在带宽探测阶段中,估计延迟始终是使用极小值,如果实际延迟真的增加了怎么办?TCP BBR 每过 10 秒,如果估计延迟没有改变(也就是没有发现一个更低的延迟),就进入延迟探测阶段。延迟探测阶段持续的时间仅为 200 毫秒(或一个往返延迟,如果后者更大),这段时间里发送窗口固定为 4 个包,也就是几乎不发包。这段时间内测得的最小延迟作为新的延迟估计。也就是说,大约有 2% 的时间 BBR 用极低的发包速率来测量延迟。
TCP BBR 还使用 pacing 的方法降低发包时的 burstiness,减少突然传输的一串包导致缓冲区膨胀。发包的 burstiness 可能由两个原因引起:- 数据接收方为了节约带宽,把多个确认(ACK)包累积成一个发出,这叫做 ACK Compression。数据发送方收到这个累积确认包后,如果没有 pacing,就会发出一连串的数据包。
- 数据发送方没有足够的数据可传输,积累了一定量的空闲发送窗口。当应用层突然需要传输较多的数据时,如果没有 pacing,就会把空闲发送窗口大小这么多数据一股脑发出去。
下面我们来看 TCP BBR 的效果如何。
首先看 BBR 试图解决的第一个问题:在有随机丢包情况下的吞吐量。如下图所示,只要有万分之一的丢包率,标准 TCP 的带宽就只剩 30%;千分之一丢包率时只剩 10%;有百分之一的丢包率时几乎就卡住了。而 TCP BBR 在丢包率 5% 以下几乎没有带宽损失,在丢包率 15% 的时候仍有 75% 带宽。
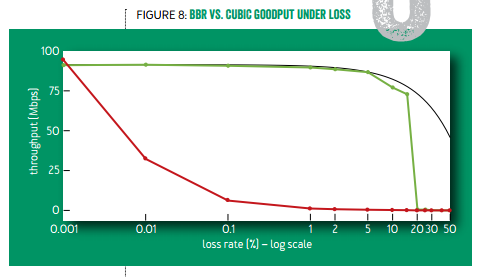
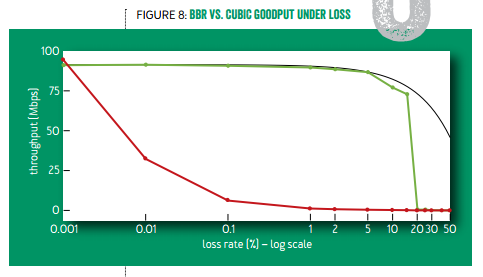
异地数据中心间跨广域网的传输往往是高带宽、高延迟的,且有一定丢包率,TCP BBR 可以显著提高传输速度。这也是中国科大 LUG HTTP 代理服务器和 Google 广域网(B4)部署 TCP BBR 的主要原因。
再来看 BBR 试图解决的第二个问题:降低延迟,减少缓冲区膨胀。如下图所示,标准 TCP 倾向于把缓冲区填满,缓冲区越大,延迟就越高。当用户的网络接入速度很慢时,这个延迟可能超过操作系统连接建立的超时时间,导致连接建立失败。使用 TCP BBR 就可以避免这个问题。
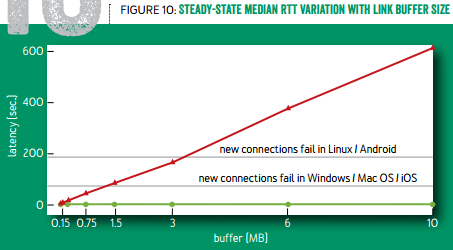
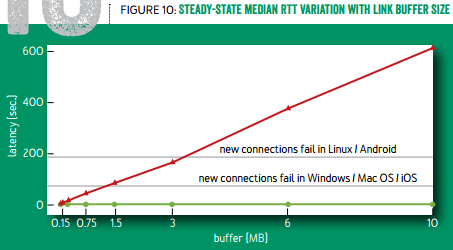
缓冲区大小与延迟的关系(红线:标准 TCP,绿线:TCP BBR)
Youtube 部署了 TCP BBR 之后,全球范围的中位数延迟降低了 53%(也就是快了一倍),发展中国家的中位数延迟降低了 80%(也就是快了 4 倍)。从下图可见,延迟越高的用户,采用 TCP BBR 后的延迟下降比例越高,原来需要 10 秒的现在只要 2 秒了。如果您的网站需要让用 GPRS 或者慢速 WiFi 接入网络的用户也能流畅访问,不妨试试 TCP BBR。
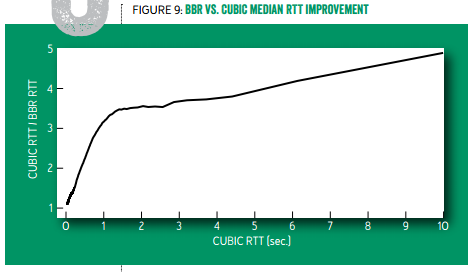
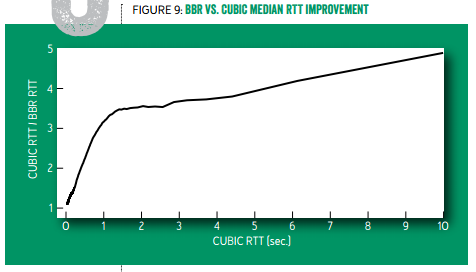
标准 TCP 与 TCP BBR 的往返延迟中位数之比
综上,TCP BBR 不再使用丢包作为拥塞的信号,也不使用 “加性增,乘性减” 来维护发送窗口大小,而是分别估计极大带宽和极小延迟,把它们的乘积作为发送窗口大小。
BBR 的连接开始阶段由慢启动、排空两阶段构成。为了解决带宽和延迟不易同时测准的问题,BBR 在连接稳定后交替探测带宽和延迟,其中探测带宽阶段占绝大部分时间,通过正反馈和周期性的带宽增益尝试来快速响应可用带宽变化;偶尔的探测延迟阶段发包速率很慢,用于测准延迟。
BBR 解决了两个问题:- 在有一定丢包率的网络链路上充分利用带宽。非常适合高延迟、高带宽的网络链路。
- 降低网络链路上的 buffer 占用率,从而降低延迟。非常适合慢速接入网络的用户。
看到评论区很多客户端和服务器哪个部署 TCP BBR 有效的问题,需要提醒:TCP 拥塞控制算法是数据的发送端决定发送窗口,因此在哪边部署,就对哪边发出的数据有效。如果是下载,就应在服务器部署;如果是上传,就应在客户端部署。
如果希望加速访问国外网站的速度,且下载流量远高于上传流量,在客户端上部署 TCP BBR(或者任何基于 TCP 拥塞控制的加速算法)是没什么效果的。需要在 VPN 的国外出口端部署 TCP BBR,并做 TCP Termination & TCP Proxy。也就是客户建立连接事实上是跟 VPN 的国外出口服务器建联,国外出口服务器再去跟目标服务器建联,使得丢包率高、延迟大的这一段(从客户端到国外出口)是部署了 BBR 的国外出口服务器在发送数据。或者在 VPN 的国外出口端部署 BBR 并做 HTTP(S) Proxy,原理相同。
大概是由于 ACM queue 的篇幅限制和目标读者,这篇论文并没有讨论(仅有拥塞丢包情况下)TCP BBR 与标准 TCP 的公平性。也没有讨论 BBR 与现有拥塞控制算法的比较,如基于往返延迟的(如 TCP Vegas)、综合丢包和延迟因素的(如 Compound TCP、TCP Westwood+)、基于网络设备提供拥塞信息的(如 ECN)、网络设备采用新调度策略的(如 CoDel)。期待 Google 发表更详细的论文,也期待各位同行报告 TCP BBR 在实验或生产环境中的性能。
本人不是 TCP 拥塞控制领域的专家,如有错漏不当之处,恳请指正。
[1] Cardwell, Neal, et al. "BBR: Congestion-Based Congestion Control." Queue14.5 (2016): 50.