在hbase中,rowkey的设计应该遵循三大原则
rowkey唯一原则
hbase中数据是以k-v格式存储的,rowkey可以类比为mysql里面的key值,因此在hbase的一张表里面,rowkey不应该重复。而且一个rowkey只能对应一条数据,用rowkey去get表里面的数据时,返回的应该是唯一一条对应的数据记录,不应该返回多条
另外,因为rowkey是按照字典顺序排序存储的,所以可以将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。不过这样做虽然方便了scan等范围查询数据,也可能会导致热点问题
rowkey长度原则
rowkey的长度原则就是说,rowkey的长度不应该过长
过长会导致rowkey在memStore中占据的内存空间过大,而实际数据占据的空间很小,只写了少量数据就因为rowkey占据太多空间而flush
因此建议越短越好,不要超过100个字节
rowkey散列原则
散列原则的作用是将数据打散,不要让连续的数据集中在一个region里面,降低热点问题出现的可能性
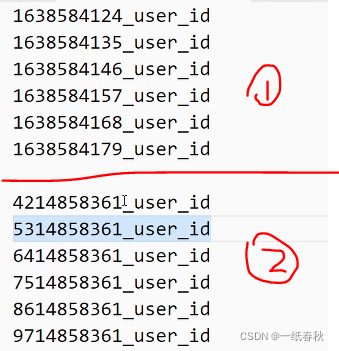
以上图的数据为例,图中的数据就是以时间戳的方式来排序,这样排序如果要访问的数据集中在某一个时间段上,这个时间段内连续的rowkey在一个region里面(因为hbase里面的数据按照字典排序,连续写入的时候就会让数据因为连续的rowkey会进入相同的region里面),对这一个region进行频繁的访问就造成了热点问题。因此应该按照散列原则,给时间戳rowkey的前面加上随机生成的散列字段,这样连续的时间戳数据也会因为随机的散列字段而进入不同的region,避免了热点问题。
当然图上并没有这么做,圈1的上半部分数据是原始数据,而圈2的下半部分选择将时间戳反转,这样每行rowkey的前几位也是各不相同的,不会被写入同一个region里面,同样避免了热点问题
热点问题
我查看了很多博客,很多博客都只说了连续的rowkey在同一个region里面就会导致热点问题,其实这样是没有说完的。因为如果只是rowkey连续,那么RegionServer会自动划分过大的region,这样每个region里面的数据量也是差不多的,不会因为这样就导致热点问题。
导致热点问题的原因是,Clinet访问查询数据时,可能会集中访问某一段连续rowkey的数据,而因为hbase中是按照字典序升序来排列数据的,这样连续将数据写入表中时,连续rowkey的数据就会被划分在同一个region里面,而针对这一段连续rowkey所在的region进行频繁大量的访问,导致region所在的节点机器承受了超出自身处理极限的访问量,从而导致效率低下甚至故障。而其他节点存储的数据因为没有被访问,所以一个节点拼死的忙,其他节点围观看戏,这就造成了热点问题。
另外还有一种情况,那就是设置的预分区不合理,同样会导致热点问题,预分区不合理同样可能导致设置的其中一个region里面的数据被大量访问。
对于热点问题,应该做的是,对rowkey进行合理的设计,让一段连续的rowkey进入不同的region当中,这样就避免了访问集中在同一个region上
以下有几个方法都可以做到:
加盐
给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,从而避免热点问题
哈希
针对rowkey进行hash运算,运算得出的结果,再拼接到原先rowkey的前面,这样连续rowkey计算得到的hash值不相同,将hash值与rowkey拼接后的新rowkey较大概率不会连续,这样就会被送入不同的region里面
但是上面也说了,这只是较大概率不会连续,但是连续的rowkey计算出来的hash值的前缀依旧可能相同。比如一段连续的rowkey,r1,r2,r3,这三者经过hash运算后的结果为aaa,aab,aac,这样虽然hash结果不同,但是hash值的前缀相同,按照字典序排序时依旧是连续的数据。
使用hash的好处是,同一个rowkey的hash值是固定的,因此查询时只要计算一下hash值,依旧可以按照rowkey查询数据。而加盐就是给每一个rowkey随机加上一个前缀,这就导致同一个rowkey,多次加盐的结果也是不同的,因此没办法再用rowkey去get到某一条数据(当然非要用rowkey去查也可以,用子串过滤器,把原来的rowkey作为子串去匹配加盐后的rowkey)
使用hash的坏处是,虽然可以继续使用get查询,但是因为计算到的hash值依旧可能连续,导致热点问题没有被解决。而加盐可以保证解决热点问题,即连续rowkey的数据一定被划分到不同的region里面
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
就比如时间戳,大量连续的时间戳只有最后两三位会改变,前面几位基本不会改变,此时就可以将最后两三位提到最前面,将重复的时间戳部分放到后面,避免了连续。
时间戳反转
时间戳反转这里的反转应该打上引号,因为这里不是将123变成321这样的反转,而是用大数减去小数,用差值作为新的rowkey
比如:现在有一段rowkey为(rowkey格式为:时间戳 + _uid)
1638620506_uid
1638620512_uid
1638620524_uid
1638620536_uid
1638620548_uid
此时需求是,让最新的记录排在最前面,也就是按照时间戳逆序排序,最新也即最大的时间戳排在最上面
方法就是设定一个大数,比如设置一个9999999999的时间戳,然后用这个时间戳去减去上面rowkey里面的时间戳,结果为
1638620506_uid ——> 8,361,379,493_uid
1638620512_uid ——> 8,361,379,487_uid
1638620524_uid ——> 8,361,379,475_uid
1638620536_uid ——> 8,361,379,463_uid
1638620548_uid ——> 8,361,379,451_uid
这样再排序的时候,按照字典序排列,最后一条rowkey,8,361,379,451_uid就会被放在第一位,实现了最新的一条记录放在最前面的需求
