prometheus的客户端与服务端
- 客户端是提供监控指标数据的一端(如写的exporter)。prometheus提供了各种语言的客户端库,需要通过Prometheus客户端库把监控的代码放在被监控的服务代码中。当Prometheus获取客户端的HTTP端点时,客户端库发送所有跟踪的度量指标数据到服务器上。详情见客户库
- 服务端是指prometheus server,拉取、存储和查询各种各种指标数据。
histogram
histogram是柱状图,在Prometheus系统中的查询语言中,有三种作用:
- 对每个采样点进行统计(并不是一段时间的统计),打到各个桶(bucket)中
- 对每个采样点值累计和(sum)
- 对采样点的次数累计和(count)
度量指标名称: [basename]的柱状图, 上面三类的作用度量指标名称
- [basename]_bucket{le=“上边界”}, 这个值为小于等于上边界的所有采样点数量
- [basename]_sum
- [basename]_count
histogram例子
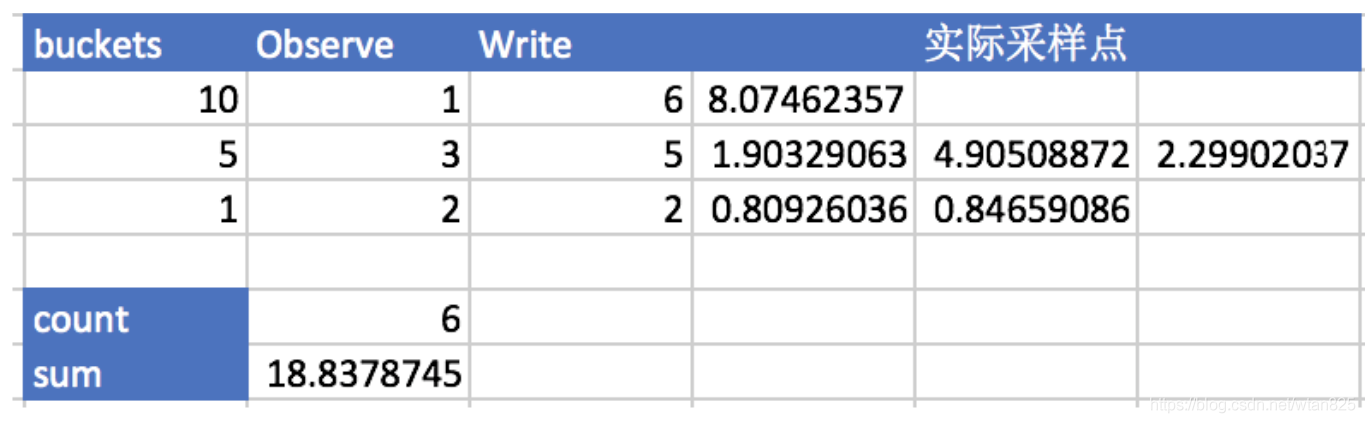
如上表,设置bucket=[1,5,10],当实际采样数据如是采样点所示, Observe表示采样点落在该bucket中的数量,即落在[-,1]的样点数为2,即落在[1,5]的样点数为3,即落在[5,10]的样点数为1,write是得到的最终结果(histogram的最终结果bucket计数是向下包含的):
[basename]_bucket{le=“1”} = 2
[basename]_bucket{le=“5”} =3
[basename]_bucket{le=“10”} =6
[basename]_bucket{le="+Inf"} = 6
[basename]_count =6
[basename]_sum =18.8378745
histogram并不会保存数据采样点值,每个bucket只有个记录样本数的counter(float64),即histogram存储的是区间的样本数统计值,因此客户端性能开销相比 Counter 和 Gauge 而言没有明显改变,适合高并发的数据收集。
histogram_quantile()函数在服务端获取summary分为数
Histogram 常使用 histogram_quantile 执行数据分析, histogram_quantile 函数通过分段线性近似模型逼近采样数据分布的 UpperBound(如下图),误差是比较大的,其中红色曲线为实际的采样分布(正态分布),而实心圆点是 Histogram 的 bucket的分为数分别被计算为0.01 0.25 0.50 0.75 0.95,这是是依据bucket和sum来计算的。当求解 0.9 quantile 的采样值时会用 (0.75, 0.95) 两个相邻的的 bucket 来线性近似。
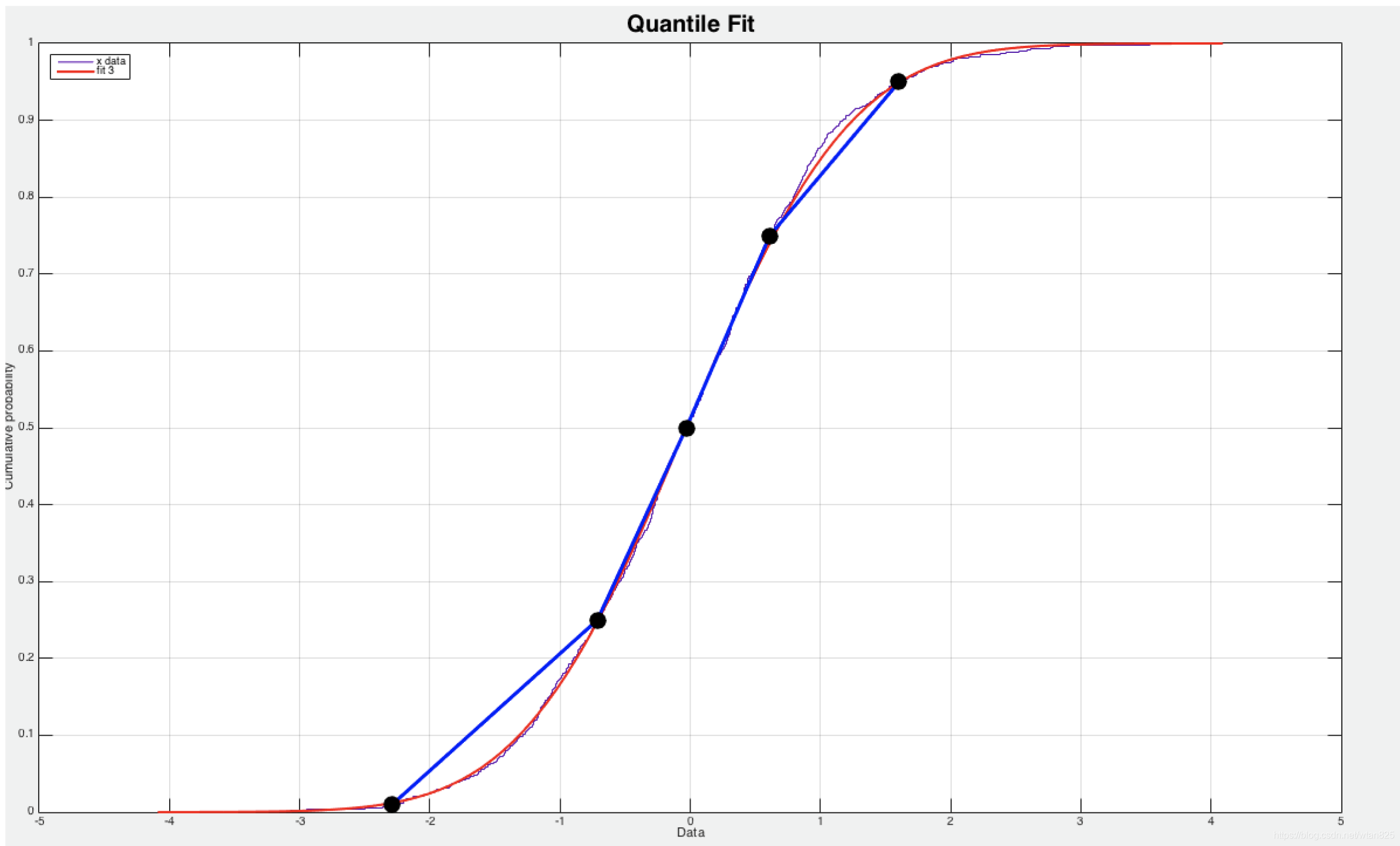
但是如果自己知道数据的分布情况,设置适合的bucket也会得到相对精确的分为数。
summary
因为histogram在客户端就是简单的分桶和分桶计数,在prometheus服务端基于这么有限的数据做百分位估算,所以的确不是很准确,summary就是解决百分位准确的问题而来的。summary直接存储了 quantile 数据,而不是根据统计区间计算出来的。
Prometheus的分为数称为quantile,其实叫percentile更准确。百分位数是指小于某个特定数值的采样点达到一定的百分比
summary是采样点分位图统计。 它也有三种作用:
- 在客户端对于一段时间内(默认是10分钟)的每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例)
- 统计班上所有同学的总成绩(sum)
- 统计班上同学的考试总人数(count)
带有度量指标的[basename]的summary 在抓取时间序列数据展示。
- 观察时间的φ-quantiles (0 ≤ φ ≤ 1), 显示为[basename]{分位数="[φ]"}
- [basename]_sum, 是指所有观察值的总和
- [basename]_count, 是指已观察到的事件计数值
summary对quantile的计算是依赖第三方库perk实现的:
github.com/beorn7/perks/quantile
summary例子
设置quantile={0.5: 0.05, 0.9: 0.01, 0.99: 0.001}
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s,90%的数据都小于等于0.014458005s。
设置每个quantile后面还有一个数,0.5-quantile后面是0.05,0.9-quantile后面是0.01,而0.99后面是0.001。这些是我们设置的能容忍的误差。0.5-quantile: 0.05意思是允许最后的误差不超过0.05。假设某个0.5-quantile的值为120,由于设置的误差为0.05,所以120代表的真实quantile是(0.45, 0.55)范围内的某个值。注意quantile误差值很小,但实际得到的分为数可能误差很大。
查看分位数时summary和histogram的选择
清楚几点限制:
- Summary 结构有频繁的全局锁操作,对高并发程序性能存在一定影响。histogram仅仅是给每个桶做一个原子变量的计数就可以了,而summary要每次执行算法计算出最新的X分位value是多少,算法需要并发保护。会占用客户端的cpu和内存。
- 不能对Summary产生的quantile值进行aggregation运算(例如sum, avg等)。例如有两个实例同时运行,都对外提供服务,分别统计各自的响应时间。最后分别计算出的0.5-quantile的值为60和80,这时如果简单的求平均(60+80)/2,认为是总体的0.5-quantile值,那么就错了。
- summary的百分位是提前在客户端里指定的,在服务端观测指标数据时不能获取未指定的分为数。而histogram则可以通过promql随便指定,虽然计算的不如summary准确,但带来了灵活性。
- histogram不能得到精确的分为数,设置的bucket不合理的话,误差会非常大。会消耗服务端的计算资源。
两条经验
- 如果需要聚合(aggregate),选择histograms。
- 如果比较清楚要观测的指标的范围和分布情况,选择histograms。如果需要精确的分为数选择summary。
